Queueing with PostgreSQL and Go
I am a huge fan of simplicity. While writing hntr, I wanted to create a powerful but easy to use tool to handle huge amounts of recon data (asset data used for security purposes). Most of the time I also use this little side-projects to play with (for me new) technologies, libs or tools.
I tried a few Go ORM tools in the past which save some time, at least up to a certain degree. The more I used those tools and especially when I wanted to use more database-specific functionality, I had to use ugly workarounds and fight the ORM. This is what led me to try something “new” and to skip a full ORM this time. More on this later.
hntr‘s main purpose is to persist, filter and display data. Job automation is only a minor functionality. Minor enough I did not want to introduce yet another dependency for. Most common queuing solutions involve a third-party tool like RabbitMQ or Redis. While they offer a lot more than just queueing and dequeuing jobs, at this stage I wanted to keep it simple. After seeing how well Oban, a job queueing lib using PostgreSQL for Elixir is working, I found this wonderful article describing the basis for a job queue in PostgreSQL. As I was already using PostgreSQL for hntr, this looked like a promising solution.
Non-blocking queueing with PostgreSQL
If you have a single worker which pulls jobs from the database, implementation is simple: Add a row to a jobs table and let workers pull jobs from the beginning of it. A simple First-In-First-out queue. Things get more complicated when there are multiple workers involved — and that’s usually the case when in need for a job queue: To distribute work load across multiple workers and make processing asynchronous.
The mentioned article describes the technique behind it in a lot more detail, but the
gist of it is: We need to ensure that retrieved rows (jobs) will only be
returned once, so no two workers are processing the same entry. To do this,
retrieved rows can be locked. The SELECT .. FOR UPDATE statement will lock
returned rows, resulting in a blocking behavior for other clients/workers doing
a SELECT on the jobs table. While we want others to ignore this rows, we don’t
want them to wait. To prevent blocking, a SELECT .. FOR UPDATE SKIP LOCKED
statement will let other clients just skip over the locked rows and return the
next batch of rows.
This is also what hntr makes use of. It’s not exactly the same as in the article, because I’m working with a job status (scheduled, finished, …) here instead of deleting the row. This is just a minor improvement to keep job data for inspection (and for their result counts).
Update 2022-10-07:: I have released a small library in Go which allows to use this mechanism very easily.
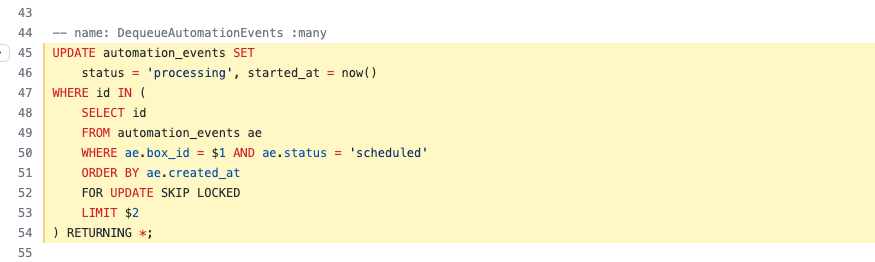
When a request is received via HTTP to get new jobs to work on, an SQL query will filter all jobs related to the current box and (skip) all locked rows. This way, no blocking will delay other workers job retrievals.
There is one caveat though: Using this technique over HTTP will result in an
eventually executed job. The purpose of using a transaction and FOR UPDATE
is to hold the rows locked as long they are worked on. This will ensure that,
when the worker crashes and not finishes the transaction, a rollback will be
executed and the jobs will be again available in the queue to be worked on.
While it would be possible to solve this using a long opened HTTP connection, I decided against this to make it simpler. It‘s not critical if a (recon) job crashes for hntr, so I’m okay with it for now.
When using hntr, all queued jobs for a box are retrievable with a HTTP call. When then call is made, a specified number of jobs will be locked in the database and returned to the caller. The caller can then process all jobs are send back all results. To make this easy for the user, hntr provides an examples Dockerfile which makes use of a simple bash script. This way, its very easy for users to integrate hntr into their workflow.
sqlc as a thin layer over SQL
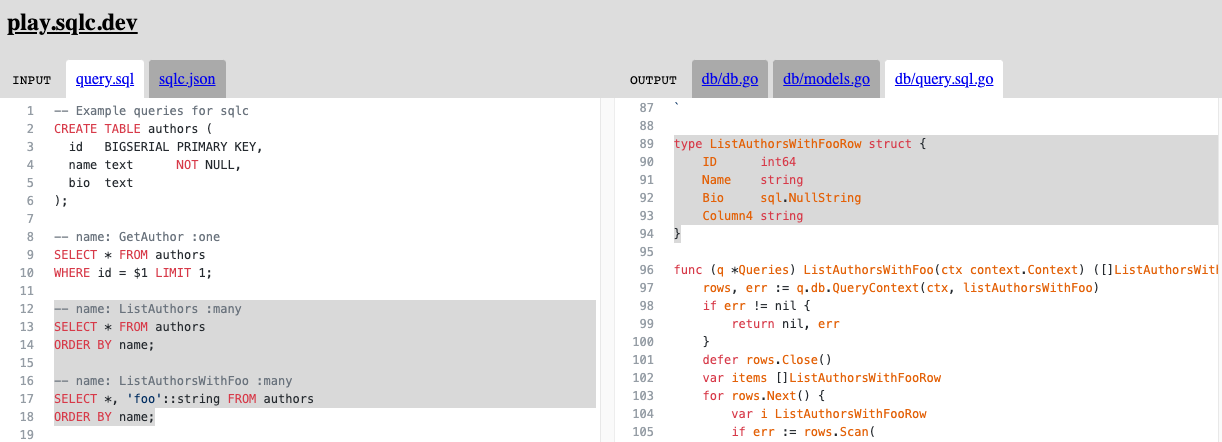
sqlc was one of the new tools I used in this project. I‘m very happy I have found this project. It feels to have the right balance between writing SQL and mapping data back into my code.
Based on a schema and queries, sqlc will generate types and functions which allow to interact type-safe via SQL. In case of PostgreSQL, sqlc is able to understand native PostgreSQL types and represent them appropriately in Go. It combines the best of two world: Powerful, handmade SQL queries with auto-generated types and functions to use them.
-- name: GetAutomationEventCounts :many
SELECT status, count(*) FROM automation_events WHERE box_id = $1 group by status;
// auto generated via sqlc
const getAutomationEventCounts = `-- name: GetAutomationEventCounts :many
SELECT status, count(*) FROM automation_events WHERE box_id = $1 group by status
`
type GetAutomationEventCountsRow struct {
Status string `json:"status"`
Count int64 `json:"count"`
}
func (q *Queries) GetAutomationEventCounts(ctx context.Context, boxID uuid.UUID) ([]GetAutomationEventCountsRow, error) {
rows, err := q.db.Query(ctx, getAutomationEventCounts, boxID)
if err != nil {
return nil, err
}
defer rows.Close()
items := []GetAutomationEventCountsRow{}
for rows.Next() {
var i GetAutomationEventCountsRow
if err := rows.Scan(&i.Status, &i.Count); err != nil {
return nil, err
}
items = append(items, i)
}
if err := rows.Err(); err != nil {
return nil, err
}
return items, nil
}
There are however some things I wish for improvement in the future. For example its not possible to define the return type of queries. The returned type is auto-generated. If you make use of a lot joins or aggregation functions, each return type will be its own row type. It’s still typesafe, however I’m not able to reuse types in this case which makes things cumbersome to work around when calling from multiple locations.
hntr is completly open-source. To view the complete job queueing with PostgreSQL and sqlc in use, head over to the repository.