hntr, shareable workspaces for target data
In the last weeks I hacked together a tool to help me organize my (temporary) target and infrastructure data I gather during audits. All existing solutions were not quite dynamic like how I wanted it to be, so this was a good hobby project for my freetime.
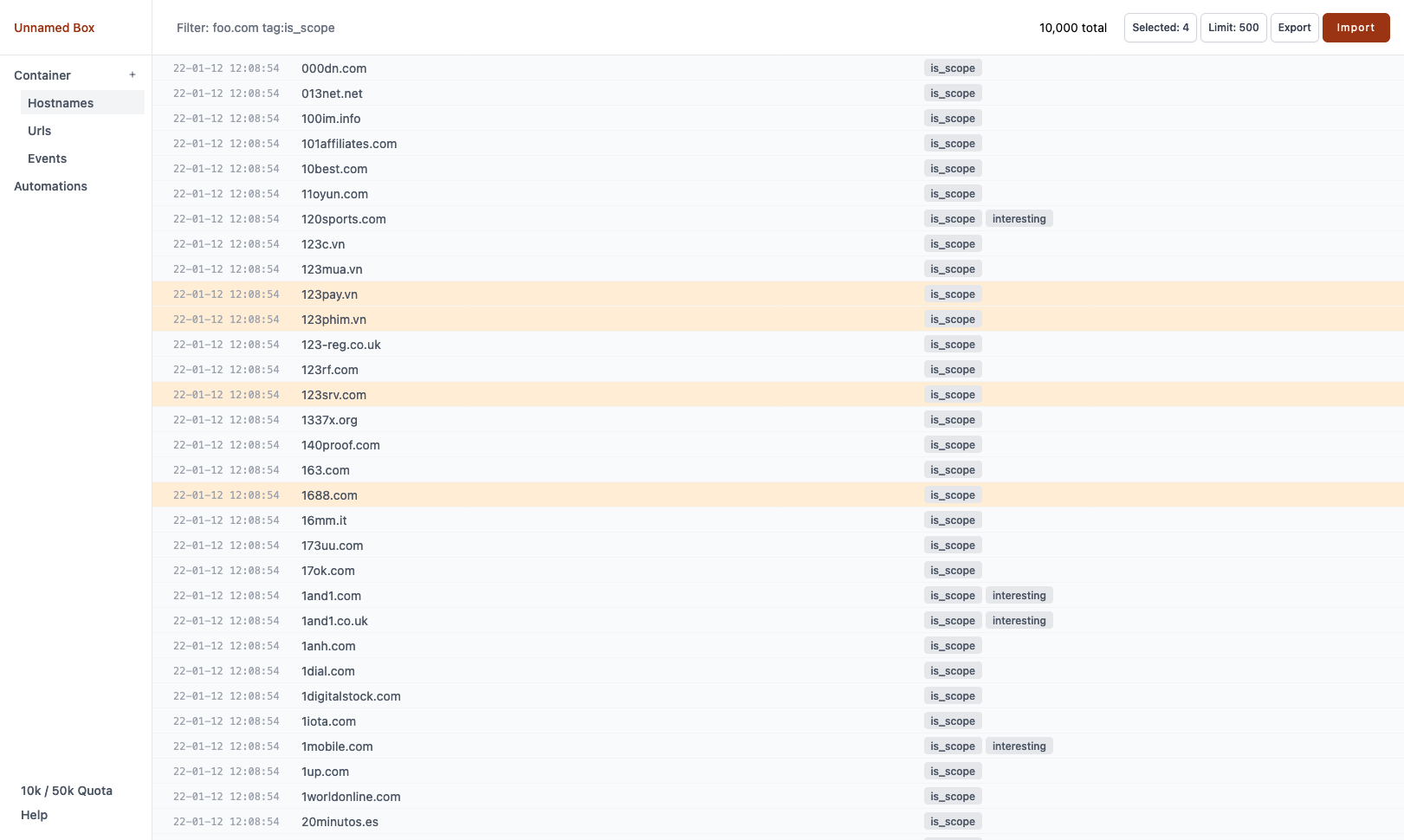
hntr (you guessed it, coming from ‘hunter’) allows to create little throwaway boxes which you can fill with data. You do not need to throw them away, but as with a code sandbox, you can use it and just forget about it. Something I really appreciate after testing and looking at a lot of different targets and scopes.
hntr is ordered by so-called containers, which act as lists. You can create multiple different containers and fill them with data. One for host names, one for urls, one for whatever you want it to be. My usual workflow is to let my data behave like a waterfall. From an initial hostnames container (x.com, y.com, sub.x.com) I will generate a services container (https://x.com, http://y.com, …), then go further with content discovery and other usefull analyzes.
To help you organize your lists, add tags to each record. This allows to add
some semantics to each single record and makes it possible to filter lists (for
automation or exporting). For example I often use tags like in_scope,
interesting, oos.
You can use curl to import or export data into and from your containers. This way you can create powerful automations:
curl https://hntr.unlink.io/records/?id=[id]&container=hostnames | httpx \
| curl https://hntr.unlink.io/records/?id=[id]&container=services
Because this is a common thing you want to parallelize, there is an
Automations section allowing you exactly to do this: Define your automation
(like running httpx on each record), schedule your whole container list and
start as much workers (which is just a simple bash script) as you want. hntr
will take care of giving each job only to a single worker.
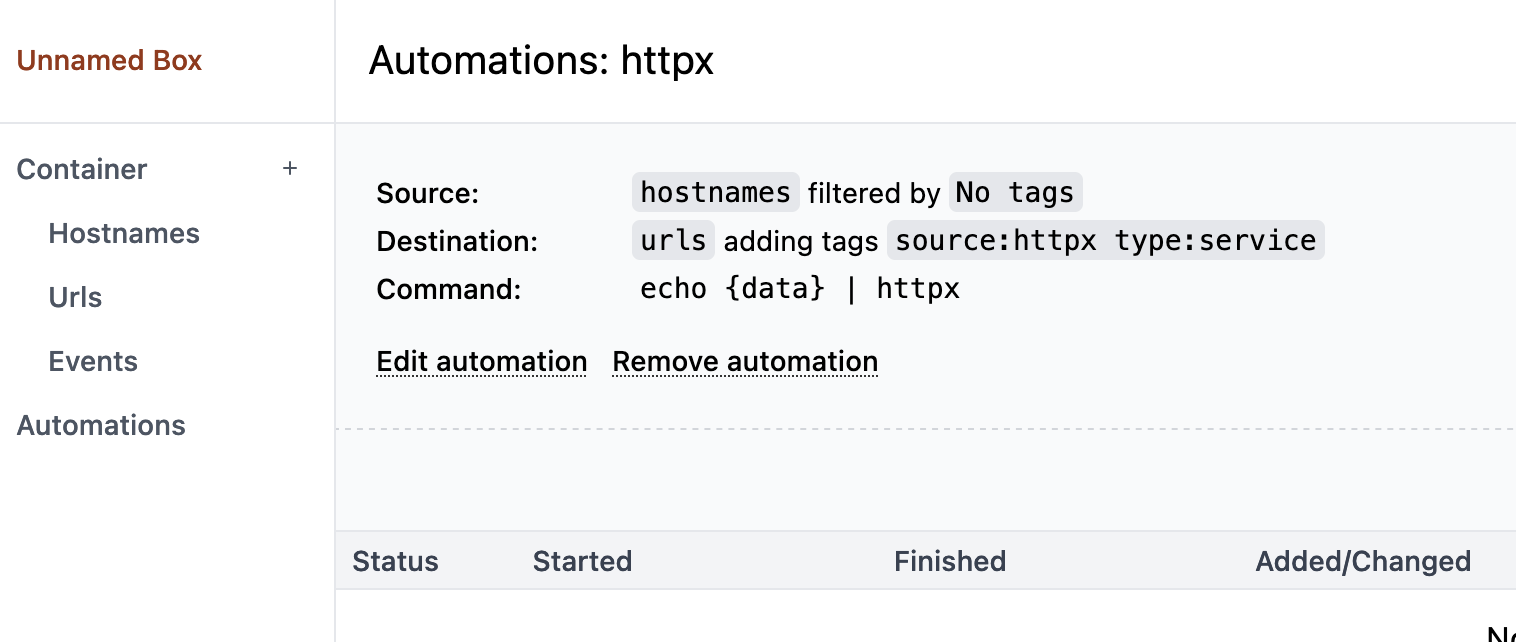
And because working together works so much better, just share the box url to collaborate on the same data sets.
I will propably add some guides in the future on the docs page.
Feel free to play, feedback is always appreciated!